$\gdef\O{\Omicron}\gdef\Ot{\tilde\Omicron}\gdef\e{\mathrm{e}}\gdef\eps{\varepsilon}$
很遗憾下半学期的没空记笔记了。有机会补。
APSP
APASP 相关更全面的算法见 我的 survey。
- [Seidel ‘95] 无向无权图 APSP $\Ot(n^\omega)$
- [Zwick ‘98] 有向无权图 APSP $\Ot(n^\mu)$,无向有权图 $1+\epsilon$ 近似 APSP $\Ot(n^\omega\epsilon^{-1}\log W)$
- [Shoshan, Zwick ‘99] 无向有权图 APSP $\Ot(Wn^\omega)$
- [Williams ‘14] 有(实数)权图 APSP $n^3/2^{\Omega(\sqrt{\log n})}$
- [Aingworth, Chekuri, Indyk, Motwani ‘96] 无向无权图 $+2$ APSP $\Ot(n^{2.5})$
- [Dor, Halperin, Zwick ‘96] 无向无权图 $+k$(偶数)APSP $\Ot(\min{kn^{2-1/k}m^{1/k},kn^{2+1/(3k-4)}})$
- [Deng, Kirkpatrick, Rong, Williams, Zhong ‘22] 无向无权图 $+2$ APSP $\Ot(n^{2.29})$
- [Dürr ‘23] 无向无权图 $+2$ APSP $\Ot(n^{2.2593})$
- [Cohen-Zwick ‘97] 无向有权图 $\times 3$ APSP $\Ot(n^2)$,无向有权图 $\times 7/3$ APSP $\Ot(n^{7/3})$,无向有权图 $\times 2$ APSP $\Ot(n^{3/2}m^{1/2})$
- [Thorup, Zwick ‘01] 无向有权图 distance oracle $\times(2k-1)$ 空间 $\O(kn^{1+1/k})$,单次查询 $\O(k)$
- [Berman, Kasiviswanathan ‘07] 无向无权图 $(2,1)$ APSP $\Ot(n^2)$
- [Dory et al. ‘23] 无向无权图 $\times 2$ APSP $\Ot(n^{2.032})$
Hitting set 的问题
如果以 $p$ 的概率选点,要覆盖所有度数 $\ge d$ 的点 $u_1,\cdots,u_t$,那么成功率是 $$ \Pr[\text{cover}(u_1)\land\cdots\land\text{cover}(u_t)]=1-\Pr[\overline{\text{cover}(u_1)}\lor\cdots\lor\overline{\text{cover}(u_t)}]\ge 1-t\Pr[\overline{\text{cover}(u_1)}]\ge 1-t(1-p)^d\ge 1-t\e^{-dp} $$ 可以取 $p=\frac{c\ln n}d$。但是问题是 $|S|$ 太大也不行。因此算法实际上做的是如果随机出来的 $S$ 没有覆盖所有的大度点,或者 $|S|$ 太大,就直接 Fail。我们假设一个阈值 $2pn$,成功率是 $$ \Pr[\text{allcover}\land |S|\le 2pn]\ge 1-\Pr[\overline{\text{allcover}}]-\Pr[|S|>2pn]\ge 1-n^{-c+1}-\e^{-pn/3}\tag{Chernoff} $$
一个简单的确定性算法如下:每次选择能覆盖最多 $\ge d$ 度点的点,记 $f(t)$ 为 $t$ 个 $\ge d$ 度点的 hitting set 大小, $$ f(t)\le f\left(t-\left\lceil\frac{td}{n}\right\rceil\right)+1\le-\log_{1-d/n}t=-\frac{\ln t}{\ln(1-d/n)}\le\frac nd\ln t $$
[Seidel ‘95]
对于邻接矩阵 $A$,考虑以下算法:
- 若 $A$ 是完全图,则直接返回。
- 递归计算 $A^2+A$ 对应邻接矩阵的距离矩阵 $D^\prime$。
- 这时 $d^\prime_{i,j}=\lceil d_{i,j}/2\rceil$。
- 计算 $P=D^\prime A$。$d_{i,j}=2d^\prime_{i,j}-[p_{i,j}<\mathrm{deg}_jd^\prime_{i,j}]$。
时间复杂度 $\O(n^\omega\log n)$。
考虑算出最短路树相关信息。定义后继矩阵 $S$,$s_{i,j}$ 表示 $\pi(i,j)$ 上 $i$ 之后第一个点。
对于 01 矩阵 $A,B$ 定义 $(A*B)_{i,j}=\set{k\mid a_{i,k}=b_{k,j}=1\text{ 中任意一个}}$,这称为 witness。那么 $S_{i,j}=(A*D^{(d_{i,j}-1)})_{i,j}$,其中 $D^{(d)}=\set{[d_{i,j}=d]}$。这样需要对于每一个 $d$ 求 witness。
优化是这样的:注意到对于 $i$ 的相邻点 $k$,$d_{k,j}-d_{i,j}\in\set{1,0,-1}$,因此只需要找 $d_{k,j}\equiv d_{i,j}-1\pmod 3$ 的 $k$ 即可,这样就减少到 $3$ 次 witness。求 witness 考虑以下算法:
- 将 $A$ 的第 $i$ 列乘 $i$。
- 枚举 $l=0\sim\log n$,对于每个 $l$ 重复 $c\log n$ 次:
- 随机取出 $A$ 的 $2^l$ 列和 $B$ 的对应 $2^l$ 行相乘得到 $C$。检查 $C_{i,j}$ 是否是个 witness,若是则记下。
- 对于 $(AB)_{i,j}\ne 0$ 但没有得到 witness 的 $(i,j)$ 暴力。
简而言之,如果 $(AB)_{i,j}=p$,那么在 $n/2\le 2^lp\le n$ 的那一轮 $l$,有大概率有恰好一对贡献的 $(a_{i,k},b_{k,j})$ 被选中。
综上所述,APSP 的距离矩阵与后继矩阵都可以在 $\Ot(n^\omega)$ 内算出。
[Dor, Halperin, Zwick ‘96]
无向无权图。这里讲过 $+2$ 的 $\Ot(n^{5/2})$,可以回顾一下。其中涉及两种做法:
- 如果只考虑最短路上的最大点度在 $a\sim b$ 之间,那么从 $\ge a$ 度点的 hitting set 出发,在只保留 $\le b$ 度点邻边的图上跑 MSSP,$\Ot(n^2b/a)$。求时枚举关键点,$\Ot(n^3/a)$。
- 如果只考虑最短路上的最大点度 $<a$ 的情况,直接在只保留 $<a$ 度点邻边的稀疏图上跑 APSP,$\O(n^2a)$。
这篇 paper 主要提了一个折中的做法,其思路是“枚举一侧 BFS 另一侧”:
- 从 $\ge a$ 度点的 hitting set 出发,在只保留 $\le b$ 度点邻边的图上跑 MSSP,然后,对于每个 $u$,在原图只保留 $<a$ 度点邻边和 hitting set 边的基础上,$u$ 向各关键点连边权为 $d_{u,\cdot}$ 的边,再跑 Dijkstra。这时,如果我们考虑 $\pi(u,v)$ 上最后一个 $a\sim b$ 度点,它之后的路径边都在图上。
这里的三类边在课件/paper 里对应的就是形如 $E_{i+1}\cup E^*\cup(\set{u}\times D_i)$。
仔细分析的话,MSSP 的复杂度是 $\Ot(n\min\set{nb,m}/a)$ 的,对每个点跑最短路还是 $\O(n^2a)$ 的。用该做法代替上面枚举关键点,取 $a=(m/n)^{1/2}$,得到 $\Ot(n^{3/2}m^{1/2})$ 的算法。
而原做法由于 $n^3/a$ 盖过了 $n^2b/a$,所以复杂度和 $m$ 无关。
现在我们将点度分三层 $n-b-a-1$:
- 最大点度 $>b$:跑原方法,$\Ot(n^3/b)$。
- 最大点度 $\in[a,b]$:跑新做法,$\Ot(n\min\set{nb,m}/a+n^2a)$。
- 最大点度 $<a$:稀疏图暴力(实际上新做法自动覆盖了这部分),$\Ot(n^2a)$。
取 $a=n^{1/3}$,$b=n^{2/3}$ 即得到 $\Ot(n^{7/3})$。
现在考虑 $+2k$ 近似,我们考虑对关键点分层,每层的关键点依赖上一层的关键点快速求出最短路,代价是近似 $+2$。
假设点度分层为 $n-s_1-s_2-\cdots-s_k=1$,$D_i$ 表示度数 $>s_i$ 的点的 hitting set。假如我们得到了 $D_i$ 到 $V$ 的 $+2k$ 近似,那么可以用新做法得到 $D_{i+1}$ 到 $V$ 的 $+2(k+1)$ 近似:
- 对于 $u\in D_{i+1}$,连上 $u$ 与 $D_i$ 的边,保留所有度数 $<s_i$ 点邻边和 hitting set 边,跑 Dijkstra。
这个的时间是 $\Ot(|D_{i+1}|ns_i)=\Ot(n^2s_i/s_{i+1})$,或者更仔细地算,$\Ot(n\min\set{ns_i,m}/s_{i+1})$。
取 $s_i=n^{1-i/k}$,得到 $\Ot(n^{2+1/k})$;取 $s_i=(m/n)^{1-i/k}$,得到 $\Ot(n^{2-1/k}m^{1/k})$。
我们发现,如果用旧方法去做这件事情,应该这样做:
- 对于 $u\in D_{i+1}$,$v\in V$,枚举 $D_1\sim D_i$ 中的点,松弛;最后,还是要只保留度数 $<s_i$ 点邻边跑 Dijkstra。
时间是 $\Ot(|D_{i+1}|n\sum_{j\le i}|D_j|+|D_{i+1}|ns_i)=\Ot(n^3/s_is_{i+1}+n^2s_i/s_{i+1})$(这个等号假定 $\set{|D_i|}$ 是等比数列)。
现在我们发现,对于前面较大的 $s_i$,$n^3/s_is_{i+1}$ 这项并非瓶颈;同时注意到,这样求出来永远是 $+2$ 近似。这一不同,是由于旧方法的证明是考虑 $\pi$ 上最大度点,而新方法的证明是考虑 $\pi$ 上最后一个超过阈值的点,所导致的。
于是,考虑分成 $t+k-1$ 层,$s_i=n^{1-i/(t+k-1)}$。对于前 $t$ 层跑旧方法,后 $k-1$ 层跑新方法,得到 $+2k$ 近似。我们希望 $n^3/s_ts_{t-1}$ 不 dominant,即 $$ 1+\frac{2t-1}{t+k-1}\le2+\frac{1}{t+k-1}\implies t\le k+1 $$ 得到 $\Ot(n^{2+1/2k})$。进一步地,仔细考虑如何保证第 $t+1$ 层是 $+4$ 近似:只需保证 $D_t$ 到 $D_{t+1}$ 是 $+2$ 近似即可。因此松弛这步可以不枚举 $v\in V$ 而是枚举 $v\in D_{i+1}$,时间变为 $n^3/s_{t+1}s_ts_{t-1}$。 $$ \frac{3t}{t+k-1}\le 2+\frac{1}{t+k-1}\implies t\le 2k-1 $$ 得到 $\Ot(n^{2+1/(3k-2)})$。进一步,注意到 $u\in D_t$ 到 $v\in D_{t+1}$ 的 $\pi$ 上如果没有度 $>s_{t-2}$ 的点,那么 $+2$ 近似可以通过在新方法的图中,$u\to$ 最后一个度 $>s_{t-1}$ 的点 $\to$ $v$,这样得到,因此无需枚举 $D_{t-1}$ 中的点作为中继点。时间降为 $n^3/s_{t+1}s_ts_{t-2}$,得到 $\Ot(n^{2+1/(3k-1)})$。
由于 $n^{1/\log_cn}=c$,故这个算法做到了 $\Ot(n^2)$ 的 $+\Theta(\log n)$ 近似。
[Deng, Kirkpatrick, Rong, Williams, Zhong ‘22]
这里讲过倍增优化,转化为 $(\min,+)$ 矩乘与稀疏图 APSP。关键在于,如果取出一棵生成树,然后将节点按欧拉序排列,只会将矩阵的大小 $\times 2$,但是,这时相邻数之差就变成 $\pm 1$ 了。根据 [Chi, Duan, Xie, Zhang ‘22],这样的 $(\min,+)$ 矩乘可以做到 $\Ot(n^{(3+\omega)/2})$。
[Berman, Kasiviswanathan ‘07]
还是倍增优化,但这里把整个 $1\sim n$ 的区间全划分了。现在不跑 $(\min,+)$ 矩乘,考虑类似于有权 $\times 2$ 的思路:
- 跑多源 BFS,找到离每个点最近的关键点。然后 $\delta(u,v)=\min\set{d(u,u^\prime)+d(u^\prime,v),d(u,v^\prime)+d(v^\prime,v)}$。
不妨设 $d(u,w)\le d(u,v)/2$。这里核心的不等式是: $$ d(u,u^\prime)+d(u^\prime,v)\le 2d(u,u^\prime)+d(u,v)\le 2d(u,x)+d(u,v)\le 2d(u,v)+2 $$ 但是由于建稀疏图实际上是保留所有度数 $<2^{i+1}$ 的点的邻边,因此 $\pi(u,v)$ 上的最大度点和次大度点的覆盖点,均可以作为中介。于是我们可以假设 $d(u,w)\le (d(u,v)-1)/2$,得到 $\le 2d(u,v)+1$。最差情况就是:
堆
| 二叉堆 | 二项堆 | 配对堆 | 左偏树 | 斐波那契堆 | |
|---|---|---|---|---|---|
| 插入 | $\O(\log n)$ | $\O(\log n)/\O(1)^\dagger$ | $\O(1)$ | $\O(\log n)$ | $\O(1)$ |
| 删除 | $\O(\log n)$ | $\O(\log n)$ | $\O(\log n)^\dagger$ | $\O(\log n)$ | $\O(\log n)^\dagger$ |
| 查 $\min$ | $\O(1)$ | $\O(\log n)$ | $\O(1)$ | $\O(1)$ | $\O(1)$ |
| 删 $\min$ | $\O(\log n)$ | $\O(\log n)$ | $\O(\log n)^\dagger$ | $\O(\log n)$ | $\O(\log n)^\dagger$ |
| 合并 | $\O(n)$ | $\O(\log n)$ | $\O(1)$ | $\O(\log n)$ | $\O(1)$ |
| decrease key | $\O(\log n)$ | $\O(\log n)$ | $\O(\log n)^\dagger$ | $\O(\log n)$ | $\O(1)^\dagger$ |
$\dagger$ 表示均摊。
注:严格来说,配对堆的那几个 $\O(1)$ 也应当视作均摊。
- [Cheriton, Tarjan ‘76] MST $\O(m\log\log n)$
- [Fredman, Tarjan ‘87] 斐波那契堆、MST $\O(m\beta(m,n))$
- [Dixon, Rauch, Tarjan ‘92] 验证 MST $\O(m)$
- [Fredman, Willard ‘92] 整数边权 MST $\O(m)$
- [Karger, Klein, Tarjan ‘95] 非确定性算法 MST $\O(m)$
- [Thorup ‘99] 非负整数边权无向图 SSP $\O(m)$
- [Chazelle ‘00] 确定性算法 MST $\O(m\alpha(m,n))$
- [Pettie, Ramachandran ‘02] 确定性算法 MST 时间等于决策树复杂度(但后者未知)
- [Haeupler, Hladík, Rozhoň, Tarjan, Tětek ‘23] Dijkstra 的 universal optimality
- [Duan, Mao, Mao, Shu, Yin ‘25] 不要求按距离顺序输出的非负权 SSP 确定性算法 $\O(m\log^{2/3}n)$
二项堆
简而言之就是二进制分组的思想。定义 $B_k$ 为 $B_{k-1}$ 的根下面接一个 $B_{k-1}$,维护 $n$ 个数,即 $n$ 个节点的二项堆形如 $$ \bigcup_{i\in\mathrm{binary}(n)}B_i $$ 其中每个 $B_i$ 中满足堆的大小关系。
- 合并:考虑二进制加法的过程。如果要合并两个 $B_i$,就把根大的那个接到根小的儿子,变成一个 $B_{k+1}$。
- 查 $\min$:扫描各根,当然也可以维护一个指针。
- 删除:decrease 成 $-\infty$ 后删 $\min$。
- 删 $\min$:拆开各个儿子,做一个形如 $(n-2^i)+(2^i-1)=n-1$ 的合并。
斐波那契堆
核心思想是弱化二项堆的结构限制,通过允许每个点少一个儿子,来允许 decrease key 直接扔到根。
对于一个堆,维护它根的链表。对于每个非根点,如果它有一个儿子在 decrease key 时被切掉了,就标记它。记 $$ \Phi(H)=\text{\# roots} + 2\times\text{\# marked nodes} $$
- 合并:直接把链表接起来。
- 查 $\min$:维护一个指针。
- decrease key:直接把这个点的子树扔到根链表。如果它的父亲没被标记过则标记,否则也扔到根链表,以此向上类推。势能函数设计得很巧妙,因此扔一次根,$\Phi$ 就减一,刚好抵掉。
- 删 $\min$:拆开各个儿子扔到根链表,然后合并儿子数相同的根。这时 $\hat T=\text{\# sons}+\text{\# roots}+\Delta\Phi=\text{\# sons}+\text{new \# roots}$。
因此要 bound 儿子数,也就是 bound $F(k)$ 表示根有 $k$ 个儿子,树的最小大小。考虑一个儿子刚接上当前点的时候,然后再去掉一个儿子: $$ F(k)\ge F(k-2)+\cdots+F(0)+F(0)\implies F=1,2,3,5,8,13,\cdots $$
优化 MST
尽管 Prim 和 Dijkstra 通过斐波那契堆都 $\O(m\log n)\to\O(m+n\log n)$ 了,但在 $m=\Theta(n)$ 时相当于没优化。考虑到严格来说复杂度是 $\O(m+n\log(\max|H|))$,因此有一个想法是,考虑强制 bound $|H|$:
- 选一个点出发做 Prim,如果堆的大小达到 $k$ 则停止。再从另一个点出发做 Prim,如果堆的大小达到 $k$,或者它这部分的树和已有的树连通了,就停止。对所有点都做上述过程。
时间为 $\O(m+n\log k)$。现在,相当于选出了一些属于 MST 的边,构成森林。将各森林合并为单点后递归做(这个思想和 Borůvka 一样)。由于每个连通块最初都必须由 $\ge k$ 个邻边的情形形成,故合并后的点数 $\le 2m/k$。因此: $$ T(n,m)\le T(2m/k,m)+\O(m+n\log k) $$ 取 $n\log k=\Theta(m)$,具体而言取 $k=2^{2m/n}$。这时相当于要解 $$ f(n)=f(2m/2^{2m/n})+1 $$ 换元。令 $r=2m/n$,$g(r)=f(n)$,则 $$ g(r)=f(2m/r)=f(2m/2^r)+1=g(2^r)+1=\cdots=\Theta(\log^*m) $$ 因此我们得到一个 $\O(m\log^*m)$ 的做法。严格来说应该是 $\O(m\beta(m,n))$,因为是从 $r=2m/n$ 开始,当 $k\ge n$ 就结束了。
https://tmt514.github.io/algorithm-analysis/index.html
并查集
- [Tarjan ‘75] 路径压缩 + 按秩合并的 $\Theta(m\alpha(m,n))$ 上下界
- [Fredman, Saks ‘89] 等价类问题的 $\Omega(\alpha(m,n))$ word operation 下界
明确一下,$rk_u$ 表示 $u$ 的子树在未经路径压缩时的高度。
分析 1
令 $\delta_u=rk_{fa_u}-rk_u$。每次 find 操作中每个点 $u$ 有两种情况:
- $2\delta_u^\prime\ge\delta_u$。由于 $rk_u=\O(\log n)$,这种情况对于每个 $u$ 只会出现 $\O(\log\log n)$ 次。
- $2\delta_u^\prime<\delta_u$。然而,$\delta^\prime_{fa_u}=\delta^\prime_u-\delta_u<\delta^\prime_u/2$,因此这种情况对于一次
find只会出现 $\O(\log\log n)$ 次。
得到 $\O((n+m)\log\log n)$ 的复杂度。
分析 2
考虑不路径压缩的最终合并树。对于路径压缩,我们从 $u$ 到当时的根连接 shortcut 边,这样形成 shortcut 图。
令 $T(m,n,r)$ 表示共 $m$ 次操作,$n$ 个点,只考虑 $rk\le r$ 的那些点以及根在这些点内的 find,总的时间。这里的参数 $r$ 是为了递归子问题用的。
现在我们划一道线,分割 $rk\le s$ 和 $>s$ 的点。对于一次 find 中将 $x$ 的父亲置为当前根 $y$ 的操作,分类讨论:
令 $m_+$ 表示 $rk_y>s$ 的 find 次数,$m_-=m-m_+$。3.1 每个 $x$ 只出现一次,3.2 每个 find 只出现一次。
$$
T(m,n,r)\le T(m_-,n,s)+\boxed{T(m_+,n/2^s,r)}+m_++n
$$
已知 $T(m,n,r)\le m+nr$。
$$
T(m,n,r)\le T(m_-,n,s)+\frac{n}{2^s}r+2m_++n
$$
取 $s=\log r$。
$$
\begin{align*}
T(m,n,r)-2m&\le T(m_-,n,s)-2m_-+2n\\
&\le \cdots\\
&\le 2n\log^*n
\end{align*}
$$
因此 $T(m,n,r)\le 2m+2n\log^*n$,将这个代回 $\boxed{}$ 得
$$
T(m,n,r)\le T(m_-,n,s)+2m_++2\frac{n}{2^s}r\log^*n+m_++n
$$
取 $s=\log^*r$:
$$
T(m,n,r)-3m\le T(m_-,n,s)-3m_-+3n\le\cdots\le 3n\log^{**}n
$$
以此类推,得到 $T(m,n,r)\le (m+n)\alpha(n)$,其中 $\alpha(n)=\min\set{c\mid\log^{\overbrace{**\cdots*}^c}n\le 3}$。
分析 3
这篇文章的大致想法是,划定从密到疏的 $0\sim z-1$ 级的 $rk$ 线,对于跨 $i$ 级线且不跨 $i+1$ 级线的边 $x-fa_x$,有两种情况:
- $x-fa_x$ 是该次
find中最后一条这样的边:每次find只有一条。(对应 3.2) - $x-fa_x$ 不是:它会多跨至少一条 $i$ 级线,最终会跨 $i+1$ 级线。(对应 3.1)
它们对应的总复杂度分别是 $mz$ 和 $\sum_i\sum_js_{i,j}c_{i,j}$,其中 $a/s/c_{i,j}$ 分别表示第 $j$ 条 $i$ 级线的划分位置/和下一条 $i$ 级线间的点数/到上一条 $i+1$ 级线所需的 $i$ 级线数。注意到 $s_{i,j}=\O(n/2^{a_{i,j}})$,因此就变成 $$ \sum_i\sum_j\frac{n}{2^{a_{i,j}}}c_{i,j} $$ 取 $c_{i,j}=a_{i,j}$,就能做到 $nz$,同时有了递推式 $a_{i+1,j}=a_{i,a_{i,j-1}}$。
容易发现,第 $i$ 级线就(不完全)对应着上一个分析中第 $i$ 次代入分析时划的 $s$ 值。如果限制 $z$ 为常数,那么最后一层会有一个 $nc_z=n\log^{**\cdots*}n$,在上一个分析中就对应递推式末尾的 $+n$;剩余层的 $nc_{i,j}/2^{a_{i,j}}$ 都是被调参抵消。
一些细节
定义 Ackermann 函数: $$ \Alpha(m,n)=\begin{cases}n+1,&m=0\\ \Alpha(m-1,1),&n=0\\ \Alpha(m-1,\Alpha(m,n-1)),&\text{otherwise}\end{cases} $$ 定义 $\alpha(n)=\min\set{k\mid A(k,1)\ge n}$……等等,怎么有两个定义啊?
首先我们可以归纳证明: $$ \Alpha(m,n)=\begin{cases}n+1,&m=0\\ n+2,&m=1\\ 2\uparrow^{m-2}(n+3)-3,&m\ne 0\end{cases} $$ 其中 $$ a\uparrow^kb=\underbrace{a\uparrow^{k-1}(a\uparrow^{k-1}(\cdots \uparrow^{k-1}a))}_{(b-1)\times\uparrow^{k-1}} $$ 而我们可以定义 $\log^{**\cdots*}$ 的反函数,例如 $\log^*n=\min\set{k\mid \underbrace{2^{2^{\cdot^{\cdot^{\cdot^{2}}}}}}_k=2\uparrow^2k\ge n}$。而 $$ \log^{**}n=\min\set{k\mid \left.\underbrace{2^{2^{\cdot^{\cdot^{\cdot^{2}}}}}}_{\underbrace{2^{2^{\cdot^{\cdot^{\cdot^{2}}}}}}_{\underbrace{\vdots}_{2}}}\right\}{(k-1)\;\underbrace{}}=2\uparrow^3k\ge n} $$ 以此类推。值得注意的是,$\log^{**\cdots*}n$ 在 $n=1,2,3,4,5$ 时总是等于 $0,1,2,2,3$,因为 $2\uparrow^{k}2\equiv 4$。这就是为什么前一个定义里要求 $\log^{**\cdots*}n\ge 3$。那么现在,Ackermann 函数和 $\log^{**\cdots*}$ 反函数的关系很明显了,因此两种 $\alpha$ 的定义只差一个常数。
$\alpha(n)$ 下界构造 [Tarjan ‘75]
对于一棵树 $T$,定义 $T(i)$ 为 $T$ 的 $i$ 级二项树:$T(0)=T$,$T(n)=T(n-1)$ 的根上挂一个 $T(n-1)$。
- 若 $T$ 有 $\ge 2$ 个节点和 $s$ 个叶子,那么 $T(\Alpha(4k,4s))$ 存在一半的叶子可以做长度为 $k$ 的
find操作。
对于 $k\le 2$ 这是显然的。现在对于 $k\ge 3$ 作归纳。先考虑 $T$ 只有两个节点,或者说 $s=1$ 的情况:
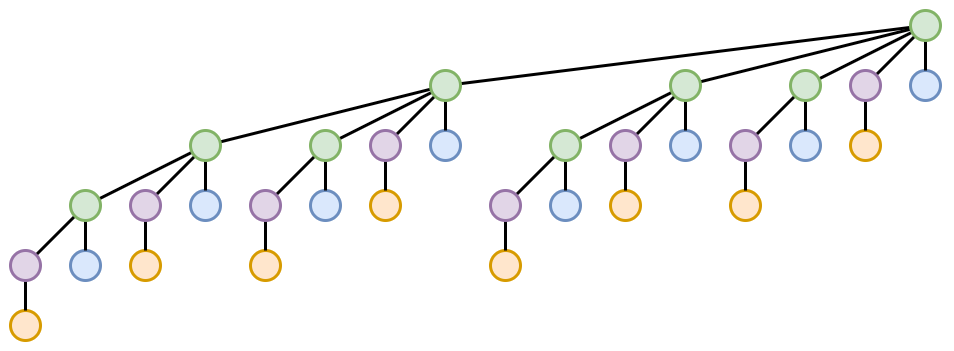
- 橙色节点的 $3/4$。
- 把所有叶子扔了,根据归纳假设,$T(\Alpha(4k-4,4)+1)$ 中有一半的紫色节点可以做长度为 $k-1$ 的
find操作,因此有一半的橙色节点可以做长度为 $k$ 的find操作。 - 在 $T(\Alpha(4k-4,4)+1)$ 中,剩余的一半紫色节点以及它们的祖先形成有 $2^{\Alpha(4k-4,4)-1}$ 个叶子的树。根据归纳假设,$T(\Alpha(4k-4,4)+1+\Alpha(4k-4,2^{\Alpha(4k-k,4)+1}))$ 中,这剩余的一半紫色节点中有一半可以做长度为 $k-1$ 的
find操作,因此有额外 $1/4$ 的橙色节点可以做长度为 $k$ 的find操作。
- 把所有叶子扔了,根据归纳假设,$T(\Alpha(4k-4,4)+1)$ 中有一半的紫色节点可以做长度为 $k-1$ 的
- 蓝色节点的 $1/4$。令 $p=\Alpha(4k-4,4)+1+\Alpha(4k-4,2^{\Alpha(4k-k,4)+1})$。在 $T(p)$ 中,只保留绿色节点,那么有 $2^{p-2}$ 个叶子。根据归纳假设,$T(p+\Alpha(4k-4,2^p))$ 中这些绿色节点叶子中有一半可以做长度为 $k-1$ 的
find操作,因此有 $1/4$ 的蓝色节点可以做长度为 $k$ 的find操作。
于是只需证明
$$
1+\Alpha(4k-4,4)+\Alpha(4k-4,2^{\Alpha(4k-k,4)+1})+\Alpha(4k-4,2^{1+\Alpha(4k-4,4)+\Alpha(4k-4,2^{\Alpha(4k-k,4)+1})})\le\Alpha(4k,4)
$$
注意,当我们说“有……的节点可以做长度为 $k$ 的 find 操作”时,就是指直接做 find 了。这时树的结构会被路径压缩改变,因此在最初的命题中,我们说的 $T$ 中可能存在 shortcut 边。同时,尽管橙色节点上的 find 会影响绿色节点的结构,但是叶子经过路径压缩还是叶子,没有祖先后代关系的点对经过路径压缩还是没有祖先后代关系,因此不影响 2,以及下面的论证。
如果 $s>1$,先扔掉一个叶子,做归纳。现在在 $T(\Alpha(4k,4s-4))$ 中已经做了一堆 find 了,但是这类扔掉的叶子及其父亲(最高 shortcut 边祖先)仍然能按上面一个叶子的情况分类并构造,最后需要证明
$$
\begin{align*}
&\Alpha(4k,4s-4)\\
+{}&\Alpha(4k-4,2^{\Alpha(4k,4s-4)+1})\\
+{}&\Alpha(4k-4,2^{\Alpha(4k,4s-4)+\Alpha(4k-4,2^{\Alpha(4k,4s-4)+1})})\\
+{}&\Alpha(4k-4,2^{\Alpha(4k,4s-4)+\Alpha(4k-4,2^{\Alpha(4k,4s-4)+1})+\Alpha(4k-4,2^{\Alpha(4k,4s-4)+\Alpha(4k-4,2^{\Alpha(4k,4s-4)+1})})})\\
\le{}&\Alpha(4k,4s)
\end{align*}
$$
这样就证明了 $\Omega(m\alpha(n))$ 的下界。
Splay & LCT
略。
ETT
考虑用平衡树维护树的欧拉序。欧拉序本质上是一个环,重定根操作相当于循环位移。具体来说,用平衡树维护欧拉序,如果将根定为 $u$,只需找到序列中的任意一个 $u$,将它之前的部分移到结尾(再去掉一个重复的原来根,加一个 $u$,这个只是维护环的小细节)即可。
link(u,v):分别makeroot(u), makeroot(v),然后把欧拉序拼起来。cut(u,v):makeroot(u)之后把序列中u, [v, ..., v], u这部分分离出来。
实现时需要维护,每个节点对应的(任意)一个平衡树中节点,以及每条边在平衡树中的位置。一个实现方法是在每个点上加一个自环,然后序列中记录每次走的边。这个的问题是,似乎动态序列中查某个数第一次出现的位置是没法做的,因此除非给定所查点的父亲,不然没法求子树信息。链信息更是不用想了。如果只维护 dfs 序的话,只能做根连父亲的动态操作。
动态图连通性
- [Holm, Lichtenberg, Thorup ‘98] (都是均摊)完全动态图连通性 $\O(\log^2n)$,只删不增动态 MST $\O(\log^2n)$,完全动态 MST $\O(\log^4n)$,完全动态边双 $\O(\log^4n)$,完全动态点双 $\O(\log^4n)$
- [Huang, Huang, Kopelowitz, Pettie, Thorup ‘16] 非确定性完全动态图连通性均摊 $\O(\log n(\log\log n)^2)$
- [Kapron, King, Mountjoy ‘13] 非确定性完全动态图连通性最坏 $\O(\log^5n)$
- [Eppstein, Galil, Italiano, Nissenzweig ‘92] 确定性完全动态图连通性最坏 $\O(\sqrt n)$
- [Pătrașcu, Demaine ‘04] 完全动态图连通性均摊 $\Omega(\log n)$
- [Chan, Pătrașcu, Roditty ‘08] 完全动态子图连通性均摊 $\Ot(m^{2/3})/\Ot(m^{1/3})$
- [Duan ‘10] 完全动态子图连通性均摊 $\Ot(m^{4/5})/\Ot(m^{1/5})$
- [Duan, Zhang ‘10] 完全动态子图连通性均摊 $\Ot(m^{3/4})/\Ot(m^{1/4})$
- [Henzinger, Krinninger, Nanongkai, Saranurak ‘15] 在 OMv hypothesis 下完全动态子图连通性的改查之积无法 $\omicron(m)$
- [Jin, Xu ‘22] 在 Combinatorial k-Clique hypothesis 完全动态子图连通性无法做到改 $\O(m^{2/3-\eps})$,查 $\O(m^{1-\eps})$
代码实现:https://etaoinwu.com/blog/fully-dynamic-connectivity/
离线的话直接线段树分治 + 并查集就行。在线的情况我们初步的想法是,维护生成森林:
add(u,v):如果 $u$ 和 $v$ 处于不同连通块,则加边;否则不管。del(u,v):如果 $(u,v)$ 是树边,需要找一条非树边把两侧连起来。
增删边连通性 [Holm, Lichtenberg, Thorup ‘98]
这个算法我觉得可以从两个角度理解:一个是离线线段树分治算法的惰性划分,一个是启发式分裂。前者可以马上帮你理解为什么莫名其妙要给边分层,不过可能还是后者更本质一些吧。就是很多时候优化的算法不是完全新想一个方式,而只是去控制暴力算法所运行的局部的 size。如果暴力算法的运行时间是线性的,那么优化之后就是 $n\operatorname{polylog}(n)$;如果是平方之类涉及“每一对 pair 的枚举”,那么优化之后就是 $n$ 的某个 $1\sim 2$ 之间的指数。
给每条边赋权 $\ell:E\to\N$,令 $E_i=\set{e\mid \ell(e)\ge i}$,我们再对于每个 $E_i$ 维护生成森林 $F_i$,这样就有

注意这里我们要求 $F_0\supseteq F_1\supseteq\cdots$,那就有个很简单的推论:一条边 $e$ 在 $0\sim \ell(e)$ 层,要么一直是树边,要么一直是非树边。
- 要求 $F_i$ 中,每棵树的大小 $\le n/2^i$。
这样,$\ell_{\max}<\log n$。
- 要求一条边的 $\ell$ 不降。且在它被枚举到时,就向上一层。
这样,总的枚举次数就是 $\O(m\log n)$,我们得到一个均摊的复杂度。

接下来,我们用 ETT 维护每个 $F_i$,时间就是 $\O(m\log^2n)$。
add(u,v):初始化 $\ell(e)=0$,这时只出现在 $E_0$ 中,如果 $E_0$ 中两端不连通,则作为树边加入 $F_0$。del(u,v):如果 $e$ 是树边,那就要将它从 $F_{0\sim\ell(e)}$ 中删去,然后需要以一种优化的方法找到新的非树边。调用reconnect(e,ℓ(e))。reconnect(e,ℓ):- 现在 $e$ 的两端在 $\ell$ 这层是两个连通块 $T_u$ 和 $T_v$,我们希望找到一条 $\ell$ 层的非树边,将两侧连起来。
- 注意 $\ell+1$ 层及以上不可能存在非树边连通两者,初始情况是由于 $F_{\ell(e)+1}\subset F_{\ell(e)}\setminus\set{e}$,后续可以归纳。
- 现在取两个连通块中较小的,不妨设为 $T_u$,枚举一端在 $T_u$ 内的 $\ell$ 层边。这样的边,要么另一端也在 $T_u$ 内,这样就提升到 $\ell+1$ 层;否则另一端必然在 $T_v$ 中,那么就将它加到 $F_{0\sim\ell}$ 中。如果全扫完了还没找到,则调用
reconnect(e,l-1)。 - 当提升到 $\ell+1$ 层时,原先在 $\ell$ 层的树边加到 $F_{\ell+1}$,非树边就不用管。
- 关键实现细节:为了枚举 $T_u$ 内的 $\ell$ 层边,我们不能枚举 $T_u$ 内的点,因为 $\ell$ 层边数可能小于点数。同时我们也无法对于每个连通块维护它的非树边,因为涉及到分裂和合并。而且为了维持 $F_{\ell}\supseteq F_{\ell+1}$,$\ell$ 层树边必须提升。一种实现是,对于每个点维护它的 $\ell$ 层邻边,同时在 ETT 中维护子树信息:当前平衡树子树中是否存在点有 $\ell$ 层邻边(注意对于同一个点,存在邻边的标记只能挂在其中一个平衡树节点上)。这样做的话,把 $T_u$ 中的所有 $\ell$ 层边用一个 dfs 拿出来会比较方便,于是可以先把它们全部提升到 $\ell+1$ 层(注意讨论树边和非树边)。这样做会在原先“提升 $m\log n$ 条边”的基础上多乘个 $\log$。
$F_i$ 性质的维持:选的是 $\le$ 原连通块一半大小的连通块。
查询可以进一步优化到 $\O(\log n/\log\log n)$。
删边 MST [Holm, Lichtenberg, Thorup ‘98]
还是维护上面那个结构,初始所有边都在 $0$ 级,$F_0$ 存 MST。每次删边,如果 $e$ 是树边,则删去后调用 reconnect(e,ℓ(e))。这里唯一不同的是,reconnect 中要按边权从小到大枚举在 $\ell$ 层的边。
我们本质上是要找 $T_u$ 和 $T_v$ 之间的 cut,即之间边权最小的边。这里的核心问题是:凭什么边权最小的边不会出现在 $<\ell$ 层?性质:
- 原边集中任意一个环,它的最大边一定在最低层。如果有 tie,表述可以修改为:存在一条最大边在最低层。
于是通过这张图就可以理解:
该性质的维持:对于一个环 $C$ 中的一条最大权最低层边 $e$,如果它被提升一层到 $\ell(e)+1$,这是 $C$ 的所有原 $\ell(e)$ 层边一定在之前已被枚举到且提升了,因为 $C$ 的所有点都在 $T_u$ 中(根据归纳假设,以及 $F_{\ell}$ 的定义)。
实现:在 ETT 中维护子树中所有点的 $\ell$ 层邻边的最小权,每次取出一条。注意这时由于 MST 的性质,如果所有边权都不同的话,是不用担心非树边升层而树边未升导致 $F_{\ell}\supseteq F_{\ell+1}$ 性质未维持的,因此不用显式提升树边。只要在边权相同 break tie 时优先选树边就行。
如果有加边的话,很简单,我们想如果加了一条边破圈了,那新边的 $\ell$ 一定得 $\ge$ 被删边的 $\ell$,那如果这样加进去违反了 $\le n/2^i$ 的要求,就无解了。
增删点连通性 [Chan, Pătrașcu, Roditty ‘08]
这个问题是说,固定图的形态,点有 on 和 off 两种状态,我们只考虑亮的点的导出子图。
算法的直觉是,考虑调用上面的算法,既然暴力加删边会由于反复切换大度点被卡,那我们首先考虑以 $\Delta$ 的间隔定期重构,只维护这段时间内被操作的点集 $Q$,这样点数限制在 $\Delta$ 以内。这时影响连通性的最讨厌的问题是形如 $Q-(V\setminus Q)-Q$ 的连边结构。对于一个 $V\setminus Q$ 中的连通块 $C$,处理它的时间是 $\deg(C)^2$。于是我们又考虑按 $\deg(C)$ 的大小分治,把大度的连通块缩起来。总而言之,最后图会被分成三部分,我们考虑它们互相影响的 $5$ 种关系,就会平衡到 $m^{2/3}$。
维护两个集合 $P$ 和 $Q$,其中初始所有点都在 $P$,$P$ 只支持删点;$Q$ 支持加删点。每 $m^{2/3}$ 次操作后重构,将所有点放回 $P$,于是 $|Q|\le m^{2/3}$。
将 $P$ 对应的导出子图的连通块中,(在原图中)度数之和 $>m^{1/3}$ 的称为 high component,其余称为 low component。
维护图 $G^*$,包含所有 $Q$ 的点以及 $P$ 中各个 high 各自缩成一个点,这样 $|V^*|\le m^{2/3}$。
再维护 $$ V\times V\supseteq\Gamma=\set{(u,v)\mid \exists\text{ low component adjacent to both }u\text{ and }v} $$ 这样 $|\Gamma|\le\sum_{\text{low }C}(\sum_{u\in C}\deg_u)^2\le m^{4/3}$。现在 $G^*$ 中加三类边:
- $Q$ 内的边
- $Q$ 和 high 之间的边(要记一个重边计数表)
- $\Gamma$
这样 $G^*$ 中的连通性与原图中的连通性等价。用前面的算法维护 $G^*$,一张 $\O(m^{2/3})$ 点 $\O(m^{4/3})$ 边的图。
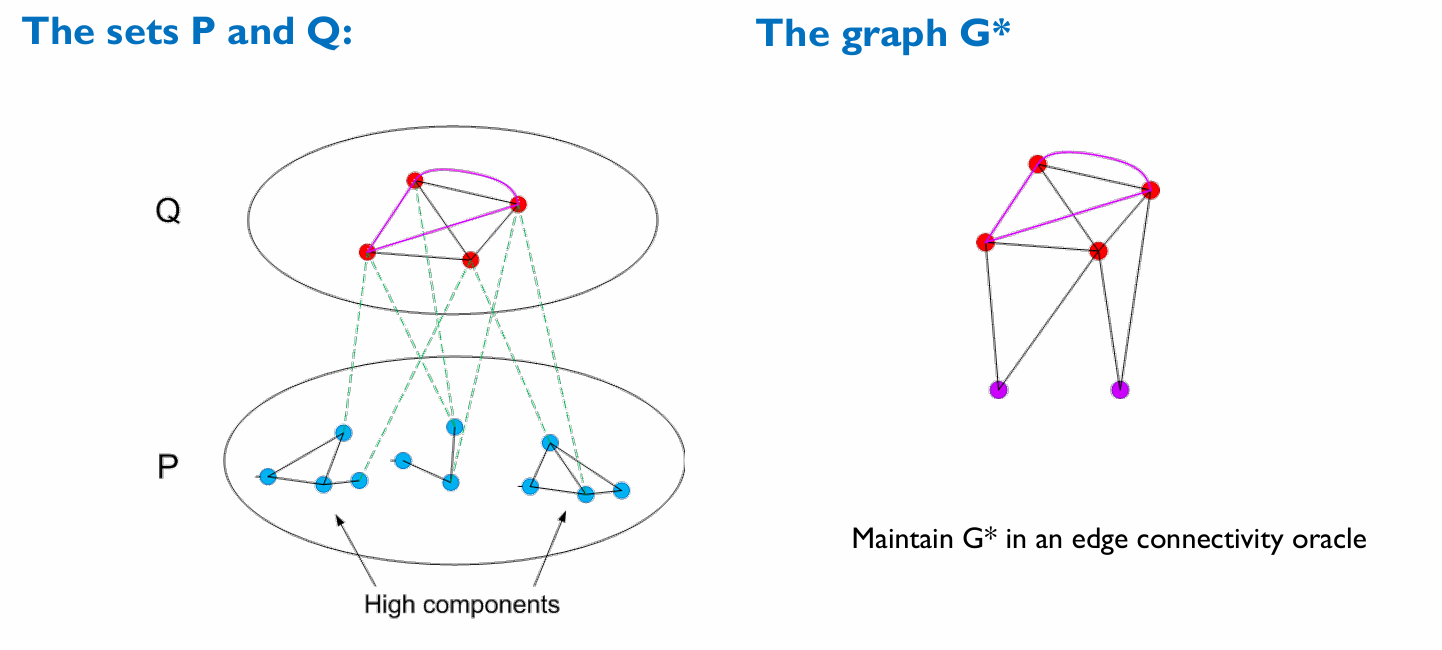
qry(u,v):如果两个点都在 $G^*$ 里就直接查。如果一个点在 low 里,就枚举和这个 low 相邻的 $G^*$ 中点。如果两个都在 low 里,就先枚举一个的邻点在 $G^*$ 的 $F_0$ 的 ETT 里标记,然后再拿另一个查。这样就是 $\Ot(m^{1/3})$ 的。add(u):一定有 $u\in Q$,直接在 $G^*$ 里暴力加边。del(u):- $u\in Q$:暴力删边。
- $u\in$ high:假设分裂为连通块 $R_1,\cdots,R_k$,按度数和从大到小排列。除 $R_1$ 以外的 high,扫描各邻边,更新 $G^*$ 的边集;变为 low 的部分,更新 $\Gamma$。这样的复杂度类似于 $\deg(R_2)+\cdots+\deg(R_j)+\deg(R_{j+1})^2+\cdots+\deg(R_k)^2$,前一部分根据启发式分裂,每轮重构是 $\Ot(m)$ 的;后一部分每轮只会有一次从 high 到 low 的情况,因此是 $m^{2/3}$ 的。关键就是别主动扫 $R_1$ 的邻边,而要在扫 $R_2\sim R_k$ 时撤掉和 $R_1$ 没边的 $G^*$ 中点。
- $u\in$ low:暴力更新 $\Gamma$。
注意还要维护 $P$ 中的每个点属于哪个连通块,这个也是随便做。每轮重构会引入 $m$ 条边,分 $m^{2/3}$ 次删去,因此均摊 $m^{1/3}$,不是瓶颈。
总的来说,每轮重构所需的时空都是 $\Ot(m^{4/3})$,每次查询 $\Ot(m^{1/3})$,每次修改均摊 $\Ot(m^{2/3})$。空间可以优化到 $\O(m)$。
网络流
Capacity Scaling
有两种实现。一种是,只取残量网络中容量 $\ge 2^i$ 的边跑;另一种是,在容量为 $\lfloor\frac{c}{2^i}\rfloor$ 的图中跑完后把容量和流量都 $\times 2$ 再加上当前二进制位。这两种每轮都至多增广 $m$ 次,所以是 $\O(m^2\log U)$ 的。
Dinic
注意复杂度的严格证明:每次流满一条边或到不了汇,都会导致当前弧更新。更新至多 $m$ 次,每次递归至多 $n$ 层。
LCT 优化:维护以汇为根的一棵内向树,每次 split(s,t) 找到 $\min$ 并全体减,删掉瓶颈边。这时如果源只能到 $u$ 了,就再找一条 $u$ 的出边加进来。如果 $u$ 的出边都用光了就删 $u$,再看 $u$ 的前驱。这样一轮就从 $\O(mn)$ 降到了 $\O(m\log n)$。
单位容量图 Dinic 复杂度
不能有重边,所以最大流 $<n$。
在 $n^{2/3}$ 轮后,$d(s,t)>n^{2/3}$,根据鸽巢存在相邻两层,点数之和 $\le 2n^{1/3}$,因此这两层之间的边数为 $\O(n^{2/3})$。这时我们就找到了残量网络上一个容量为 $\O(n^{2/3})$ 的割,因为根据 bfs 的性质不会有跨越 $\ge 2$ 层的正向边。
在 $m^{1/2}$ 轮后,根据鸽巢存在相邻两层之间的边 $\ge m^{1/2}$,同样得到一个割。由于单位容量图是流一条边就没一条边,故一轮为 $\O(m)$,于是对于单位容量图有了一个 $\O(m\min\set{n^{2/3},m^{1/2}})$ 的算法,结合 capacity scaling 得到一个 $\O(m\min\set{n^{2/3},m^{1/2}}\log U)$ 的算法。
对于二分图,在 $n^{1/2}$ 轮后,每条增广路长度都 $>n^{1/2}$。二分图的性质导致一个点不可能被两条流流过,换句话说流可以分解成点不交的路径。于是剩余至多增广 $n^{1/2}$ 轮,复杂度就是 $\O(m\sqrt n)$。
无向单位容量图
我们有 LCT 优化 Dinic,又有鸽巢 bound 流量,现在考虑结合起来。但是问题是,单位容量图里 Dinic 一轮已经是 $\O(m)$ 了,还能咋优化?所以考虑退回到 EK。
对于无向图,找路径相当于动态图连通性问题,而我们可以说明无向单位容量网络流中有流(即有流)的边不多:
- 无环流至多用 $\O(n^{3/2})$ 条边。
假设残量网络上 $s$ 到 $t$ 的最短路长为 $d$,则(和上面的说法一样)可流的流量不超过 $(n/d)^2$。换句话说,如果剩余流量为 $v$,那么 $s$ 到 $t$ 的最短路不超过 $n/\sqrt v$。这就说明,以 EK 的方式去增广,流经的边数不超过 $$ \frac{n}{\sqrt n}+\frac{n}{\sqrt{n-1}}+\cdots+\frac{n}{\sqrt1}\le \int_0^nx^{-1/2}\mathrm{d}x=\O(n^{3/2}) $$ 我们知道 EK 不会产生环流,如果有另一个边更多的最大流可以在上面跑 EK 然后对称差搞出环。因此命题得证。
现在的想法是,如果每次只流 $1$ 的流量,那么没必要考虑全部无向边,只需要取一个生成森林即可。于是 bfs 的边数就是 $\O(n^{3/2})$。增广时从动态图连通性的那个结构里取边就行。复杂度瓶颈在 bfs,总时间 $\O(n^{5/2})$。
最小割与 $k$-连通性
以下 Karger 的都是非确定性算法。
- [Karger ‘92] 无向图全局最小割 $\Ot(mn^2)$
- [Karger, Stein ‘93] 无向图全局最小割 $\Ot(n^2)$
- [Karger ‘93] 无向图全局近似最小割常数近似比 $\Ot(m)$
- [Benczúr, Karger ‘96] 无向图有源汇近似最小割常数近似比 $\Ot(n^2)$
- [Karger ‘98] 无向图全局最小割 $\Ot(m)$
- [Karger, Levine ‘02] 无向图最大流 $\Ot(m+nv)$
- [Nagamochi, Ibaraki ‘92] sparse $k$-connectivity (both edge & vertex connectivity) certificate $\Ot(m)$
Finding the edge connectivity:https://www.sciencedirect.com/science/article/pii/S0022000085710227
Karger 算法
适用于无向有权图。
考虑以下神秘算法:每次(按权重)随机选一条边,把两端点合并。保留重边。剩下两个点的时候就得到一个割。
设最小割为 $c$,如果最小割上的边都没被选到,则该算法正确。每个点的度数都 $\ge c$,因此边数 $\ge cn/2$,这是随机选一条边未选到割中的边的概率为 $$ \frac{\frac{cn}{2}-c}{\frac{cn}2}=\frac{n-2}n $$ 因此正确概率至少为 $$ \frac{n-2}{n}\times\frac{n-3}{n-1}\times\frac{n-4}{n-2}\times\cdots\times\frac13=\frac{2}{n(n-1)} $$ 不牛。
接下来是很精妙的一步:考虑到,如果合并到中途停下来,最小割仍有很大概率是还在的。因此考虑合并到一定时候,再多轮随机。进一步递归这一想法,我们就想到:从初始情况开始,合并到剩余 $f(n)$ 个点时,就复制两份分别继续合并(递归),返回两种情况结果的较小值。分析概率的递归式我们会看出,选择 $f(n)$ 使得 $$ \frac{n-2}{n}\times\frac{n-3}{n-1}\times\frac{n-4}{n-2}\times\cdots\frac{f(n)+2}{f(n)+1}=\frac12 $$ 时是最平衡的。容易看出应当取 $f(n)\approx n/\sqrt2$。这样会得到 $2\log_2n$ 层的二叉树。实现上我们不需要每合并一条边就重构整张图。论文里给的做法是维护每对点之间的边数,我感觉是不是用并查集就行。反正递归树叶子数是 $n^2$ 的,所以不管怎样时间都是 $\Ot(n^2)$。
记 $P(n)$ 为成功率,有 $$ P(n)=1-\left(1-\frac12P\left(\frac{n}{\sqrt2}\right)\right)^2=P\left(\frac{n}{\sqrt2}\right)-\frac14P\left(\frac{n}{\sqrt2}\right)^2 $$ 课上讲的神奇代换是 令 $Q(n)=4/P(n)-1$,得到 $$ Q(n)=Q(n/\sqrt2)+1+\frac{1}{Q(n/\sqrt2)}=2\log_2n+\sum_i\frac1{Q(n/2^{i/2})}=\Theta(\log n) $$ 问 chatgpt,给了个更精确的渐进式: $$ P(2^{n/2})=\frac{4}{n+\log n+C+\omicron(1)} $$ (话说这种二次递推不等式我在 ML 也见过,似乎关键一步都是代换倒数,感觉应该是个通法)
因此只需 $\Ot(1)$ 轮就可以 w.h.p.,总时间 $\Ot(n^2)$。
直觉上来说,该分治算法利用的是各步正确率的不均匀性。可以验证,如果每步的正确率是常数 $1-\epsilon$,则分治是无法优化时间的。
最初的暴力算法还神奇地证明了:最小割数量 $\le\binom n2$。考虑 union bound,由于最后只会给出一个割,所以不同的割之间是不重合的,union bound 取等。所以超过 $\binom n2$ 个最小割,概率就 $>1$ 了。达到上界的构造是一个环。
近似全局最小割
论文里有讲有权的做法,时间复杂度不变。这里我们只考虑无权。
整体思路是说,对每条边只以某概率保留,然后在采样后的边集上跑最小割,得到的最小割在原图中一定不会差太多。
- 如果最小割为 $c$,则容量 $\le\alpha c$ 的割有 $\O(n^{2\alpha})$ 个。
大概口胡的证明:用一样的方法,缩到剩余 $\lfloor 2\alpha\rfloor$ 个点之后,随机选择 $S$ 返回。对于一个容量 $\le \alpha c$ 的割,得到该割的概率至少为 $$ \begin{align*} &\frac{n-2\alpha}{n}\times\frac{n-1-2\alpha}{n-1}\times\cdots\times\frac{1-{2\alpha}}{1+\lfloor 2\alpha\rfloor}\times 2^{-\lfloor 2\alpha\rfloor+1}\\ ={}&\frac{\Gamma(n-2\alpha+1)}{\Gamma(1-{2\alpha})}\frac{\Gamma(1+\lfloor 2\alpha\rfloor)}{\Gamma(n+1)}2^{-\lfloor 2\alpha\rfloor+1}\\ \ge{}&\Theta\left(\frac{\Gamma(n-2\alpha+1)}{\Gamma(n+1)}\right)\\ ={}&\Theta(n^{-2\alpha}) \end{align*} $$ 倒数第二步类似于 $2^{-n}n!=\Omega(1)$;最后一步用斯特林公式展开一下。另外如果 ${2\alpha}$ 很接近 $1$ 的话可以取到剩余 $\lfloor 2\alpha\rfloor+1$ 个点。
对于一个容量为 $v$ 的割,如果以 $p$ 的概率保留每条割边,那么我们知道对于 $\epsilon\in(0,1)$,剩下割边数 $v^\prime$ 满足 $$ \Pr[(1-\epsilon)pv\le v^\prime\le(1+\epsilon)pv]\ge1-2\e^{-\epsilon^2pv/3} $$ 因此如果取 $p=C\ln n/\epsilon^2c$($c$ 是最小割),得到的概率就是 $1-\operatorname{poly}(n)^{-1}$,这个是对于单个割而言的。对于所有割,至少有其中一个在采样后的图中偏差过大的概率,根据 union bound 不超过 $$ \int_1^{+\infty}2\e^{-\epsilon^2p\alpha c/3}\mathrm{d}(n^{2\alpha})=\int_1^{+\infty}n^{-C^\prime\alpha}\mathrm{d}(n^{2\alpha}) $$ 取个大点的 $C$ 就行了。这样一来,再调下参,w.h.p. 取样后的图的最小割在原图中容量 $\le(1+\epsilon)c$。
如果使用 [Gabow ‘95] 的 $\Ot(mc)$ 算法求最小割,总的时间就是 $\Ot((m/c)c)=\Ot(m)$。
近似有源汇最小割
上面的做法不适用于有源汇最小割,因为最小割数量的 bound 的证明假设了每个点度数 $\ge c$。在有源汇的情况下,例如可以考虑 $s$ 和 $t$ 之间是 $s\to 1\to t$、$s\to 2\to t$、……,这样就有 $2^{n/2}$ 种最小割。在这种情况下 union bound 就炸了。核心的点在于,$s-t$ 最小割 $m$ 可能远大于全局最小割 $c$。
一个想法是,如果一条边只出现在相当大的割中,那么它还是能像上面那样采样的。对于一条边,定义它的(普通)连通性为,其两端点的最小割。定义一条边是 $k$-strong 的,当且仅当它的两端在同一个 $k$-边连通分量中,定义强连通性 $c_e=\max\set{k\mid e\text{ is }k\text{-strong}}$。$k$-边连通分量的定义就是极大的最小割恰为 $k$ 的子图。容易看出,一条边的强连通性 $\le$ 普通连通性。
根据上面的分析我们的直觉是,对于 $k$-边连通,以 $\Theta(\ln n/\epsilon^2k)$ 密度采样,误差可以接受。我们希望保证采样后割的期望不变,因此如果以 $p_k$ 的概率选择 $k$-连通边,那么边权要设置为 $1/p_k$。但这样不行,原因见下。
需要按照强连通性采样,也就是对于 $k$-strong 边,以 $\Theta(\ln n/\epsilon^2k)$ 密度采样。这样:
- w.h.p. 所有割都偏差不超过 $\epsilon$。
- w.h.p. 图只有 $\O(n\ln n/\epsilon^2)$ 条边。
第一个的分析不能直接用 Chernoff。[Benczúr, Karger ‘96] 给出了一个引理:
- 边 $e$ 的容量为随机变量 $X_e$,则以 $1-\operatorname{poly}(n)^{-1}$ 的概率,任何一个割的偏差都不超过 $\pm\epsilon$ 倍,这里 $\epsilon=\sqrt{C\frac{M}{\hat c}\log n}$,其中 $\hat c$ 是最小期望割,$X_e$ 满足 $0\le X_e\le M$。
容易发现无源汇那边给出的分析是一个特例($X_e$ 是 Bernoulli 随机变量)。当 $X_e$ 不只取 $\set{0,1}$ 时,就得用 Hoeffding 而不是 Chernoff 证了,但是我怀疑这个引理 state 得有问题,我怀疑 $M$ 应该在根号外面。不管怎样,当我们以不均匀的密度采样时,直接用这个引理给出的 $\epsilon$ 太大了。
魔改的证明思路是,把整个采样过程拆分为:依次在仅由 $[2^i,+\infty)$-strong 边构成的图(也就是所有 $2^i$-边连通分量)中采样 $[2^i,2^{i+1})$-strong 的边,这时 $M/\hat c=2$。于是近似比就是 $(1\pm\epsilon)^{\log m}$ 这样的一个东西。仔细分析可以得到 $1\pm\epsilon\log m$。在子阶段的分析中设置非单位容量可以进一步得到 $1+\epsilon$。
需要用强连通性而不是普通连通性的原因就在于这里的分析。如果用普通连通性,会发现 $\ge k$ 的边组成的子图的最小割不一定 $\ge k$。最简单的例子是 $E=\set{(s,t),(s,1),(1,t),(s,2),(2,t),\cdots,(s,n-1),(n-1,t)}$,这里 $(s,t)$ 的普通连通性是 $n$ 而强连通性是 $2$。
第二个我们通过证 $\sum1/c_e\le n$ 来说明。考虑一个连通块的最小割 $C$。根据 $k$-strong 的定义,这个连通块里的所有边 $c_e\ge|C|$,因此 $\sum_{e\in C}1/c_e\le |C|/|C|=1$。删掉 $C$ 之后归纳(删边只会使 $c_e$ 变小)即可。最后用 Chernoff bound。
现在用 LCT 优化最大流就可以做到 $\Ot(n^2)$,但是我们难以求得 $c_e$,只能考虑近似。
接下来会说明,存在算法,可以求出所有 $c_e<k$ 的边的一个超集 $S_k$,并且 $|S_k|<k(n-1)$。由于把 $c_e$ 估小是不会出错的,因此可以求出 $S_1,S_2,S_4,S_8,\cdots$,把 $S_{2^i}\setminus S_{2^{i-1}}$ 当中的边的 $c_e$ 估为 $2^{i-1}$。这样采样之后图的边数期望还是 $$ \frac{\ln n}{\epsilon^2}\sum_i\frac{|S_{2^i}|}{2^{i-1}}=\O\left(\frac{n\log^2n}{\epsilon^2}\right) $$ 另外有一个命题刚好和 $S_k$ 的大小上限 match:
- $\ge k(n-1)$ 条边的图一定有一个 $k$-边连通分量,于是 $c_e<k$ 的边数 $<k(n-1)$。
证:考虑最小的反例 $G$,也就是 $G$ 有 $\ge k(n-1)$ 条边,且没有 $k$-边连通分量。那么 $G$ 的最小割 $c<k$。取走这个割,剩下的两个连通块也不含 $k$-边连通分量。因此边数 $<k(n_1-1)+k(n_2-1)+k=k(n-1)$,矛盾。
定义一个 sparse $k$-connectivity certificate 为 $G$ 的一个子图,满足:
- 包含所有普通连通性 $\le k$ 的边。
- 边数 $\le k(n-1)$。
- 对于每个割 $C$,在 $H$ 当中的容量 $\ge\min\set{|C|,k}$。
构造:每次取 $G$ 的一个生成森林。这里的关键是取生成森林是把能使连通的边都尽量取了。
证明:对于一个容量为 $c$ 的割,如果某轮取得了其中 $t<c$ 条边,那么下一轮的生成树根据定义一定会再取至少一条。
重复该构造 $2\log_2n$ 次可以包含所有强连通性 $<k$ 的边。考虑将所有 $k$-边连通分量缩点,得到的图就没有 $k$-边连通分量,于是边数 $<k(n-1)$。因此有一半的点度 $\le 2k$。每 $2$ 次可以将一半的点变为孤点,因此 $2\log_2n$ 次就行。
取 $n$ 次生成森林,时间 $\O(nm)$,反而成为瓶颈。
求 $k$-连通边 [Nagamochi, Ibaraki ‘92]
以下算法能在 $\O(m)$ 时间内给出整个划分 $F_1,\cdots,F_k$:
对于每个点维护一个 $r$,表示它在 $F_1\sim F_r$ 中已经连有父亲。每次取未考虑的,$r(u)$ 最大的点 $u$,对于其未考虑的邻边 $e=(u,v)$,将 $r(v)$ 加一并将 $e$ 加入 $F_{r(v)}$。
直觉上来说,它是在“并行地增广”多个生成森林。取 $r(u)$ 最大的点的直觉是,你需要保证 $u$ 能把它的邻点“纳入”自身已处于的生成森林里。如果不取最大,就会导致“本来应该早在 $r$ 层取的边,放到 $r^\prime>r$ 层才取”:
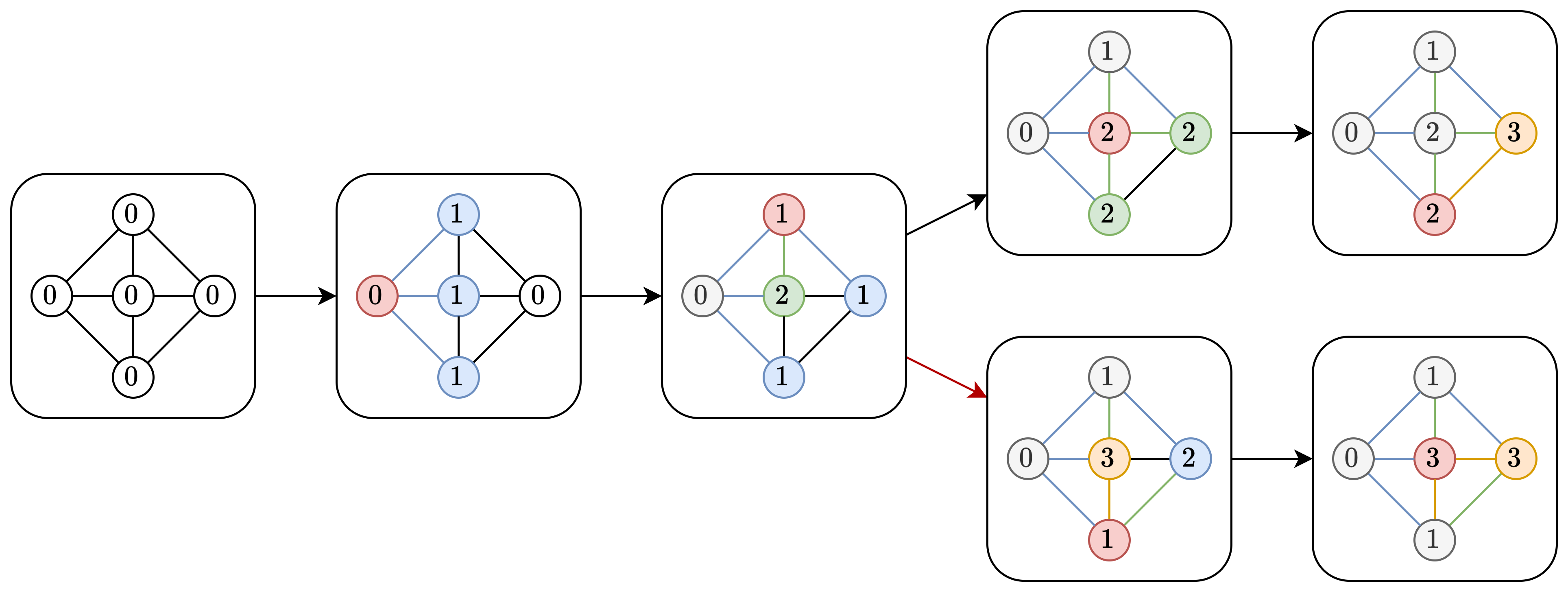
严格的证明是通过归纳证明以下命题:
- 若 $(u,v)\in F_k$,则 $u,v$ 在 $F_1\sim F_{k-1}$ 中都连通。
该命题与正确性命题等价:
- $u,v$ 在 $F$ 的某个前缀中连通。(如果 $u,v$ 在 $F_k$ 中连通,那么 $F_k$ 中存在路径 $u-x_1-\cdots-x_t-v$,那么 $u,x_1$、$x_1,x_2$、……、$x_t,v$ 在 $F_1\sim F_{k-1}$ 中都连通,于是 $u,v$ 在 $F_1\sim F_{k-1}$ 中连通。)
将这两个命题同时归纳,然后反证。若 $(u,v)\in F_k$ 但 $u,v$ 在 $F_{k-1}$ 中不连通($k\ge 2$),那么首先 $u$ 和 $v$ 在 $F_{k-1}$ 中各自从属于一个非单点连通块 $T_u$,$T_v$。对于 $T_u$ 和 $T_v$ 我们都可以如下刻画其生成过程:首先树中第一条边被加入时,两端的 $r$ 应该都是 $k-2$,此后该树扩张的过程中,选择的点 $r$ 一定 $\ge k-1$。这说明,不妨设 $T_u$ 的第一条边先被加入,那么在 $T_u$ 扩展到目前状态的过程中,$T_v$ 中的点是没有机会被选择的,因为第一条边加不进来。从而当 $(u,v)$ 加入 $F_k$ 时,$v$ 在 $F_v$ 中是个孤点,矛盾。
一些归约矩乘的问题
现代的矩乘方法都很复杂,时间复杂度自动忽略 $\log$ 因子,下面不写 $\Ot$。
- [Matoušek ‘91] Dominance product $\O(n^{(3+\omega)/2})$
- [Vassilevska, Williams, Yuster ‘07] $(\max,\min)$ 矩乘 & APBP $\O(n^{2+\omega/3})$
- [Shapira, Yuster, Zwick ‘07] APBP(点权)$\O(n^{2+\mu})$
- [Duan, Pettie ‘09] $(\max,\min)$ 矩乘 & APBP $\O(n^{(3+\omega)/2})$
- [Vassilevska ‘08] APNP $\O(n^{(15+\omega)/6})$
- [Duan, Jin, Wu ‘18] APNP $\O(n^{(3+\omega)/2})$
$(\min,+)$ 矩乘
用 $x^{a_{i,j}}$ 代替 $a_{i,j}$,这样单次运算变成多项式乘法。对于值域在 $[0,M]\cup\set{+\infty}$ 的 $(\min,+)$ 矩乘,可以在 $\O(Mn^\omega)$ 完成。
无权有向图 APSP
直接暴力做就是 $\log n$ 次 $(\min,+)$ 矩乘,但是值域每次倍增。这里的想法是,如果 $d(u,v)$ 比较大,那随便抽几个点(松弛)就能抽到 $\pi(u,v)$ 上的点。令 $r=3/2$,$D_i$ 表示所有距离 $\le r^i$ 的点对都正确求出的距离矩阵。对于一对距离为 $r^{i+1}$ 的点对 $(u,v)$,有 $r^{i+1}/3$ 个中间点 $w$ 离 $u$ 和 $v$ 的距离都 $\le r^i$。随机取大小为 $s$ 的子集 $B\subseteq[n]$,w.h.p. $D_{i+1}=(D_i)_{[n],B}(D_i)_{B,[n]}$。我们要求: $$ \left(1-\frac{s}{n}\right)^{r^{i+1}/3}=\operatorname{poly}(n)^{-1} $$ 取 $s=Cn\ln n/r^i$ 即可。因此总复杂度为 $$ \sum_i\min\Set{r^in^{\omega(1,1-i/l,1)},n^{3-i/l}}=\sum_i\min\Set{n^{i/l+\omega(1,1-i/l,1)},n^{3-i/l}} $$
其中 $l=\log_rn$。第一项(指数)递增,第二项递减。忽略整数要求,平衡到 $n^{2.53}$ 这样。这个指数叫 $2+\mu$。
Maximum Witness
对于 01 矩乘,定义 maximum witness $$ (A*B)_{i,j}=\max\set{k\mid A_{i,k}=B_{k,j}=1} $$ 想法是,先定位出 $\max k$ 处于哪一段,再暴力。一个思路是令 $$ A^\prime_{i,k}=\begin{cases}\left\lfloor\frac{k}{n^{1-r}}\right\rfloor,&A_{i,k}=1\\ -\infty,&A_{i,k}=0\end{cases},\quad B^\prime_{k,j}=\begin{cases}\left\lfloor\frac{k}{n^{1-r}}\right\rfloor,&B_{k,j}=1\\ -\infty,&B_{k,j}=0\end{cases} $$ 然后以 $\O(n^{\omega+r})$ 的时间做值域为 $n^r$ 的 $(\max,+)$ 矩乘,再 $\O(n^{3-r})$ 暴力。$\O(n^{(3+\omega)/2})$。
实际上这样反而是麻烦了。直接将 $A$ 的列分为 $n^r$ 块,$B$ 的行分为 $n^r$ 块,对应块以 $\O(n^{\omega(1,1-r,1)})$ 做 $(\lor,\land)$ 矩乘,这样就是 $\O(n^{2+\mu})$。
近似 $(\min,+)$ 矩乘与近似 APSP
近似的意思是求得的值在实际值的 $[1,1+\epsilon]$ 倍内,所以首要的是不能估小。
若值域范围大,可以通过 $\lceil Ra_{i,j}/M\rceil$ 缩小值域,最后再乘 $M/R$。但是这样近似比不均匀,例如 $M=25$,$R=5$:

但是没法完美地做到每个值都是 $1+\epsilon$ 的近似比,因为没了步长均匀性,就没法转化为值域更小的矩乘。直觉是,对于每段 $[2^i,2^{i+1})$ 内的值做不同的缩放:$\lceil Ra_{i,j}/2^{i+1}\rceil$,这样和理想情况只差一个常数。近似比为 $$ \max_{a=2^i}^{2^{i+1}}\frac{\frac{2^{i+1}}{R}\left\lceil\frac{R}{2^{i+1}}a\right\rceil}{a}<\max_{a=2^i}^{2^{i+1}}\frac{a+\frac{2^{i+1}}{R}}{a}=1+\frac2R $$ 实际做的时候,对于 $a_{i,k}+b_{k,j}$,我们只能期望在 $\max\set{a_{i,k},b_{k,j}}$ 所在的那层求得。缩放值时,也是将 $>2^{i+1}$ 的值直接设为 $+\infty$。因此最终的近似比应当形如 $$ \max_{a=2^i}^{2^{i+1}}\max_{b=0}^{2^{i+1}}\frac{\frac{2^{i+1}}{R}\left\lceil\frac{R}{2^{i+1}}a\right\rceil+\frac{2^{i+1}}{R}\left\lceil\frac{R}{2^{i+1}}b\right\rceil}{a+b}<\max_{a=2^i}^{2^{i+1}}\max_{b=0}^{2^{i+1}}\frac{a+\frac{2^{i+1}}{R}+b+\frac{2^{i+1}}{R}}{a+b}<\max_{a=2^i}^{2^{i+1}}\frac{a+2\cdot\frac{2^{i+1}}{R}}{a}=1+\frac4R $$ 总的时间就是 $\O(n^\omega\epsilon^{-1}\log M)$。APSP 就是 $\epsilon$ 要多除以个 $\log_2n$。
Dominance Product
定义 dominance product $$ (A\diamond B)_{i,j}=\left\lvert\Set{k\mid A_{i,k}\le B_{k,j}}\right\rvert $$ 注意到所有比较只发生在各个 $k$,$A$ 的第 $k$ 列和 $B$ 的第 $k$ 行之间。将 $\set{A_{\cdot,k}}\cup\set{B_{k,\cdot}}$ 排序为 $L_k$ 后,剩下的就是一个一维偏序型的贡献。要把它归约到矩乘,就需要双方独立,不能有这样一个偏序关系,这个要求在一些 ds 问题中我们见过,是用 cdq 分治优化的。那么这里只能分块了。
将 $L_k$ 分为 $n^r$ 段 $[L_{k,1},\cdots,L_{k,n^r}]$。对于块内,暴力贡献,时间为 $(n/n^r)^2n^r\cdot n=n^{3-r}$。对于块间,可以这样写贡献:令 $(A_b)_{i,k}=[A_{i,k}\in L_{k,b}]$,$(B_b)_{k,j}=[B_{k,j}\in L_{k,b}]$。那么总的答案应为 $$ \sum_bA_b\sum_{b^\prime>b}B_b $$ 需要 $n^r$ 次矩乘,时间 $n^{r+\omega}$。平衡取 $r=(3-\omega)/2$ 即得 $\O(n^{(3+\omega)/2})$。
$(\max,\min)$ 矩乘与 APBP
$$ (A\circ B)_{i,j}=\max_k\min\set{A_{i,k},B_{k,j}} $$
这个东西和 dominance product 有些关系。注意到 $$ (A\circ B)_{i,j}=\max\Set{\max_{k\mid A_{i,k}\le B_{k,j}}A_{i,k},\max_{k\mid A_{i,k}>B_{k,j}}B_{k,j}} $$ 因此只需考虑求 $$ D_{i,j}=\max_{k\mid A_{i,k}\le B_{k,j}}A_{i,k} $$ 一个大致的思路就是,通过 dominance product 判断(某一段值域内)有没有 $A_{i,k}\le B_{k,j}$(相当于剪枝),有的话就逐一检查。
将 $A$ 的第 $i$ 行按值域分为 $r$ 段 $[L_{i,1},\cdots,L_{i,n^r}]$,类似地令 $(A_b)_{i,k}=[A_{i,k}\in L_{i,b}]A_{i,k}$,然后求 $A_b\diamond B$。求 $D_{i,j}$ 时,先找到 $A$ 的第 $i$ 行的最大段,和 $B$ 的第 $j$ 列在 dominance product 中结果非零,然后暴力枚举块内的每个元素去判断。暴力的部分时间为 $n^{3-r}$。
有一个结果是,稀疏的 dominance product($A$ 有 $m_1$ 个非 $+\infty$,$B$ 有 $m_2$ 个非 $-\infty$)可以做到 $\O(\sqrt{m_1m_2}n^{(\omega-1)/2})$。因此这里的时间为 $n^r\sqrt{n^{2-r}n^2}n^{(\omega-1)/2}=n^{(3+\omega+r)/2}$。平衡即得 $n^{2+\omega/3}$,即 $\omega$ 和 $3$ 的右三等分点。
很自然的想法是把 $B$ 也分段了。和 dominance product 不同的是,后者比较的是 $A$ 的第 $k$ 列和 $B$ 的第 $k$ 行的每一对元素,而现在需要比较的是 $A$ 的第 $i$ 行和 $B$ 的第 $j$ 列的对应位元素,所以不能形如“将 $\set{A_{i,\cdot}}\cup\set{B_{\cdot,j}}$ 排序”。考虑将所有元素,即 $\set{A_{i,j}}\cup\set{B_{i,j}}$ 排序后分成 $2n^r$ 段,这时问题就分为两部分:
- $A_b\diamond B_b$,这时 $m_1=m_2=n^{2-r}$,因此总的只有 $\O(n^{(3+\omega)/2})$。
- $A_{\in b}\sum_{b^\prime>b}B_{\in b^\prime}$,这个部分和 dominance product 一样,就是正常矩乘,$\O(n^{r+\omega})$。
同样我们对 $A$ 的第 $i$ 行找到最大的 $b$ 使得存在第 $b$ 段中的 $A_{i,k}\le B_{k,j}$,暴力枚举其中的元素检查,$\O(n^{3-r})$。总的就是 $\O(n^{(3+\omega)/2})$。
但是由于是全局排序,可能单行内各段元素数量就不均匀。这个容易处理。对于第 $b$ 段,将 $A$ 的第 $i$ 行所有在第 $b$ 段内的元素再排序,如果有 $c$ 个,就再拆成长为 $n^{1-r},\cdots,n^{1-r},c\bmod n^{1-r}$ 的段。令 $A^{\prime\prime}_b$ 为只包含最后那段的矩阵,$A^{\prime}_b$ 则是将各个行的每个长为 $n^{1-r}$ 的段分到不同的行(各元素的列位置不变)的矩阵(由于总共就 $n^{2-r}$ 个第 $b$ 段的数,所以原大小的矩阵能容下)。然后分别做上面的两种,复杂度不变。